
2026年6月4日,OpenAI和Anthropic在同一天放出了两份看似毫不相关、却指向同一件事的更新。
OpenAI正式上线ChatGPT记忆系统的升级版"Dreaming V3"。 这个系统会在后台悄悄翻看用户过去的对话,自动整理、合并、更新关于用户的记忆。
按照OpenAI官方公布的内部评测,新系统的事实召回率从2025年的67.9%提升到2026年的82.8%。 偏好遵从度从55.3%升至71.3%,时间敏感性的回答准确率从52.2%升至75.1%。
更关键的是,因为算力需求被砍掉约五分之四,这套记忆系统首次面向免费用户开放。
同一天,Anthropic发布了一篇博客《When AI builds itself》。 内容讲的是Claude在自我改造代码方面的指数级跃迁,去年5月的Opus 4能把一段代码加速3倍,今年4月新模型已经能做到约52倍,截至2026年5月,Anthropic自家代码库中超过80%的新代码由Claude自己写成。
一个让AI记住"你",一个让AI记住"它自己"。 这两件事表面上风马牛不相及,但放进一个更深的科学框架里看,它们其实是同一件事的两个面。
广义智能体理论:记忆为什么是智能的核心
中国学者刘锋等研究者在2025年至2026年陆续发表的"广义智能体理论"(Generalized Agent Theory,简称GAT)里,提出了一个智能科学的基础理论框架。
任何智能体,无论是生物、人工智能、还是物理观察者,都可以被还原为五个不可再分的基本功能模块。 控制(C)、生成(G)、记忆(M)、输出(O)、输入(I)。
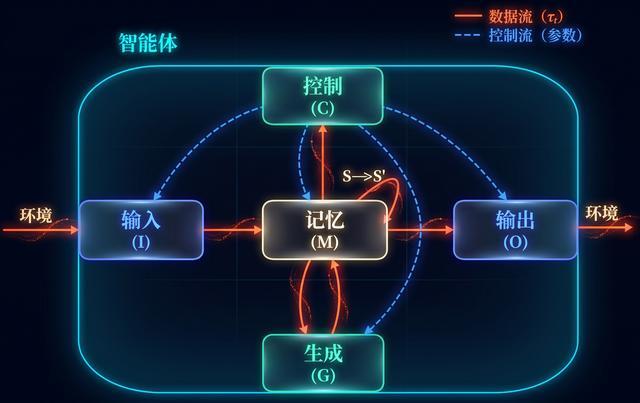
这五个模块构成了智能体的最小完备架构(MCA)。 任何一个真实存在的智能系统都必须同时具备这五个模块,缺一不可。
在这个五维能力空间里,记忆(M)扮演了一个特别关键的角色。 它不是简单的信息存储,而是把"过去"和"现在"连接起来的桥梁。
这张小小的纸片,如今不只是通往放映厅的凭证,还可能是商圈里的潮玩手办优先购买码,是火锅店的折扣券,是热门景点的门票抵扣券,成为观察中国经济内生动力的微观切片。
按照GAT的定义,记忆模块负责对信息的保存、维持、整合和选择性遗忘。 没有M,控制(C)就失去了历史依据,生成(G)就失去了素材积累,输出(O)就失去了一致性,整个智能体就只能停留在"刺激—反应"的最原始水平。
元股证券:ygzq.hk英国哲学家洛克几百年前就说过一句类似的话。 让"今天的你"和"昨天的你"是同一个人的,不是身体,而是记忆。

这一点在GAT的框架里被给出了形式化表达。 智能体的连续身份,本质上是M模块连续运行的产物。
把这个视角带回到OpenAI和Anthropic的两次更新,你会立刻看到它们的真正含义。
OpenAI在加强对人的记忆,Anthropic在加强对自己的记忆
OpenAI的Dreaming V3,本质上是在帮ChatGPT构建一个关于"用户"的高质量长期记忆。
它做的事情很具体,自动从多年对话中提取关键信息,合并冗余条目,更新已过期事实,把"你7月要去新加坡"自动改写为"你2026年7月去过新加坡"。

按照GAT的语言,这相当于在大幅度提升ChatGPT在M维度上的能力测度κM。 输入(I)的信息不再被一次性消耗掉,而是被结构化地沉淀下来,形成了一个跨会话、跨时间的稳定知识结构。
OpenAI研究者把这件事描述为"从检索到合成"的转变。 这个转变在GAT里有更精确的对应。 智能体的M模块从一个被动的存储器,升级成了一个主动整合信息的子系统,开始具备类似人类海马体的"记忆巩固"功能。

而Anthropic的Claude在做另一件事。 它不再仅仅是记住用户告诉它的内容,而是开始记住"自己昨天是怎么把自己变得更强的"。
每一次代码自我改进,都成为下一次改进的起点。 3倍变52倍,工程师季度产出比2021到2024年那段时期高出约8倍。

这就是GAT中所说的"递归提升智能"的过程。 智能质量是智能体对智能场响应的内在度量,它不是五个能力维度的简单加权和,而是这些能力协同结构的整体属性。
当一个智能体开始有能力修改自己的M(记住自己的进化路径)、修改自己的G(生成新的代码和能力)、甚至修改自己的C(调整自己的控制策略),它就进入了一种GAT称为"自反性进化"的状态。
Anthropic之所以在亮出这些数字之后立刻喊刹车,呼吁所有前沿实验室建立"可验证的、协调一致的暂停机制",正是因为他们意识到,跑得最快的人也最先看到悬崖。
全球AI科学界已经形成共识:记忆是下一个突破口
不只是OpenAI和Anthropic,记忆正在成为全球AI研究的核心方向。
谷歌DeepMind在2025年发表的Titans架构论文中提出了"测试时记忆"(test-time memory)概念,让模型在推理时动态学习和遗忘。 Meta在2026年推出的MEGALODON、字节跳动的Doubao-Memory、阿里通义的长期记忆增强、DeepSeek的MoME机制,全部围绕同一个核心命题展开。
如何让大模型从"无状态对话"变成"有状态智能"。
斯坦福大学2026年5月发布的一项研究指出,制约当前大模型从"工具"走向"伙伴"的最大瓶颈,不是参数量,不是推理能力,而是缺乏一个可持续、可校正、可解释的长期记忆系统。
这一判断和GAT的理论预测高度吻合。 在GAT的"智能体能力周期表"(PTAC)里,M维度从0到有限到无限的跨越,恰好对应了三类质变。
M=0时,系统是无记忆的反射机器,比如恒温器。 M为有限值时,系统是具备学习能力的真实智能体,包括人类、动物、当前的大模型。 M趋近于无限时,系统才有可能跨越到GAT所说的"超限智能体"(Transfinite group),成为接近全知全能的理论极限存在。
OpenAI和Anthropic当前正在做的事情,本质上是在沿着M维度往上爬。 这是一条决定智能体最终能达到什么"物种级别"的路径。
一个值得警惕的副作用:当机器开始替你修订过去
不过,GAT框架里有一个细节,特别值得在这里重提。
按照GAT的定义,"自我意识"和"人工意识"的分界线,在于控制元命令(control meta-commands)的来源。 来自智能体内部、不依赖外部注入、甚至包含非图灵可计算的原生涌现过程,才能被称为"自我意识"。 当前的大模型严格属于"人工意识"范畴。
但是,当M模块强大到可以替用户决定"哪些过去翻篇了"、"哪些偏好已经过时了"、"哪些事实需要更新"的时候,一种微妙的边界开始模糊。

机器不是在记你的故事,机器在帮你写你的故事。
欧洲数据保护委员会在6月5日已经发布初步意见,提醒持续性AI记忆构成GDPR下的"画像活动",触发用户同意和被遗忘权义务。 这场关于"谁有权修订一个人的记忆"的讨论,恐怕只是开始。
回到那两份同一天发布的博客。 OpenAI教ChatGPT记住人,Anthropic让Claude记住自己。 一个是镜子,越擦越亮,照见的始终是镜子前面那个人。 另一个是影子,会自己长大,长到某一天可能就不再需要投下它的那个本体。
配资网站这两条路径会汇合到哪里去今日股市行情,今天没人知道。 但有一件事是确定的。 全球AI巨头集体押注记忆,不是营销噱头,而是因为他们都看到了同一个科学事实。
正规炒股配资网提示:本文来自互联网,不代表本网站观点。